Batch OCR
Optical Character Recognition (OCR) is the use of computer algorithms to detect text information from images. If OCR tools are activated in your Symbiota portal, you can use OCR to attempt to parse textual information from pictures of, e.g., specimen labels and enter data into the appropriate fields from there. Instructions for using batch OCR processes are provided below. For instructions for using OCR in the Occurrence editor, see the OCR page in the Editor Guide.
Batch Generating OCR for Records in a Portal
To run OCR on many specimen images at a time
- Navigate to your Administration Control Panel (My Profile > Occurrence Management > name of collection).
- Click Processing Toolbox.
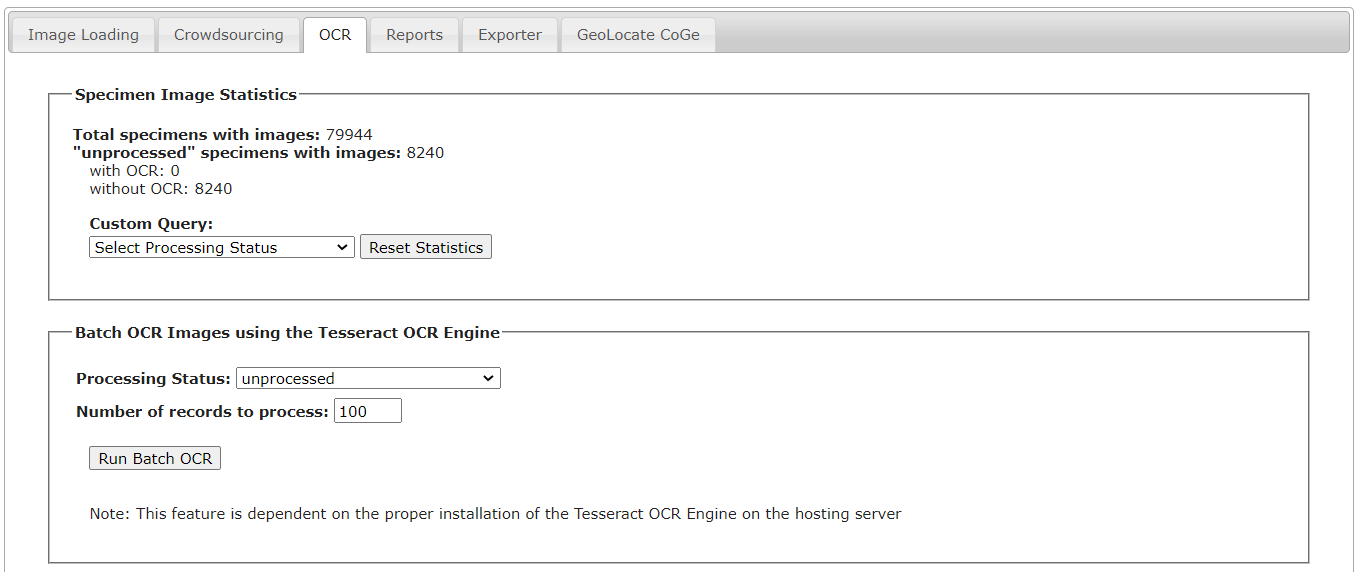
- If OCR is enabled in your portal, click the OCR tab.
- From here, you can view how many specimens have a saved OCR output, and you can run OCR on a designated number of specimens using the Batch OCR Images using the Tesseract OCR Engine box. Indicate the processing status of the records for which you would like to run OCR in the “processing status” field, and indicate how many of these records you would like to run at one time using the “Number of records to process” field.
A video tutorial of this process is shown here:
Uploading Pre-Generated OCR
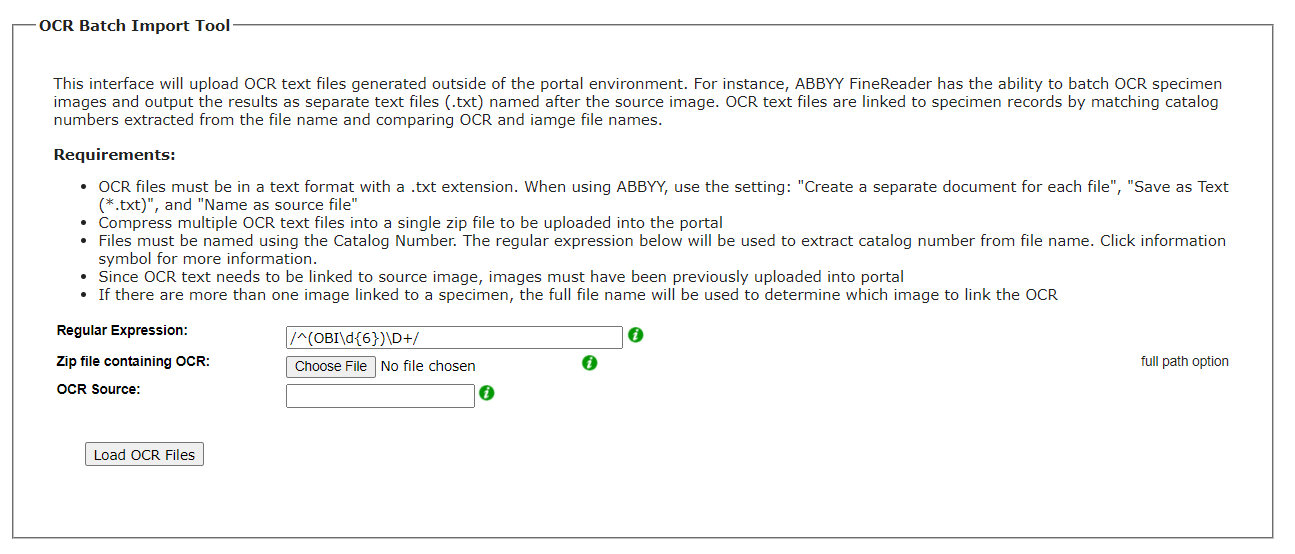
Some portals also include an interface into which you can upload OCR text files generated outside of the portal environment. For instance, ABBYY FineReader has the ability to batch OCR specimen images and output the results as separate text files (.txt) named after the source image. OCR text files are linked to specimen records by matching catalog numbers extracted from the file name and comparing OCR and iamge file names.
This tool can also be found on the OCR tab in the Processing Toolbox.
To upload a file, make sure your collection and files meet the following requirements:
- OCR files must be in a text format with a .txt extension. When using ABBYY, use the setting: “Create a separate document for each file”, “Save as Text (*.txt)”, and “Name as source file”
- Compress multiple OCR text files into a single zip file to be uploaded into the portal
- Files must be named using the Catalog Number. The regular expression below will be used to extract catalog number from file name.
- Since OCR text needs to be linked to source image, images must have been previously uploaded into portal
- If there are more than one image linked to a specimen, the full file name will be used to determine which image to link the OCR
Cite this page:
Katie Pearson. Batch OCR. In: Symbiota Support Hub (2025). Symbiota Documentation. https://biokic.github.io/symbiota-docs/coll_manager/edit/ocr/. Created on 03 Dec 2021.